前面的文章介绍了MongoDB副本集和分片集群的做法,下面对MongoDB集群的日常维护操作进行小总结:
MongDB副本集故障转移功能得益于它的选举机制。选举机制采用了Bully算法,可以很方便从分布式节点中选出主节点。Bully算法是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。别的节点可以选择接受这个声称或是拒绝并进入主节点竞争。被其他所有节点接受的节点才能成为主节点。节点按照一些属性来判断谁应该胜出。这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)。
1)MongoDB集群的节点数量
官方推荐MongoDB副本集的成员数量最好为奇数,且选举要求参与的节点数量必须大于成员数的一半。假设MongoDB集群有3个节点,那么只要有2个节点活着就可以选举;如果有5个,那么活3个节点就可以选举;如果有7个节点,那么活4个就可以选举.....MongoDB集群最多允许12个副本集节点,其中最多7个节点参与选举。这是为了减少心跳请求的网络流量和选举话费的时间,心跳每2秒发送一次。MongoDB集群最多12个副本集节点,是因为没必要一份数据复制那么多份,备份太多反而增加了网络负载和拖慢了集群性能;而最多7个节点参与选举是因为内部选举机制节点数量太多就会导致1分钟内还选不出主节点,凡事只要适当就好。2)MongoDB心跳
整个MongoDB集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉。MongoDB节点会向副本集中的其他节点每两秒就会发送一次pings包,如果其他节点在10秒钟之内没有返回就标示为不能访问。每个节点内部都会维护一个状态映射表,表明当前每个节点是什么角色、日志时间戳等关键信息。如果是主节点,除了维护映射表外还需要检查自己能否和集群中内大部分节点通讯,如果不能则把自己降级为secondary只读节点。3)MongoDB同步
MongoDB副本集同步分为初始化同步和keep复制。初始化同步指全量从主节点同步数据,如果主节点数据量比较大同步时间会比较长。而keep复制指初始化同步过后,节点之间的实时同步一般是增量同步。初始化同步不只是在第一次才会被处罚,有以下两种情况会触发: [1] secondary第一次加入,这个是肯定的。 [2] secondary落后的数据量超过了oplog的大小,这样也会被全量复制。=============================================================================================
何为oplog? oplog(应用日志)保存了数据的操作记录,oplog主要用于副本,secondary复制oplog并把里面的操作在secondary执行一遍。但是oplog也是mongodb的一个集合,保存在local.oplog.rs里;然而这个oplog是一个capped collection,也就是固定大小的集合,新数据加入超过集合的大小会覆盖,所以这里需要注意,跨IDC的复制要设置合适的oplogSize,避免在生产环境经常产生全量复制。oplogSize可以通过--oplogSize设置大小,对于Linux 和Windows 64位,oplog size默认为剩余磁盘空间的5%。在mongodb主从结构中,主节点的操作记录成为oplog(operation log)。oplog存储在一个系统数据库local的集合oplog.$main中,这个集合的每个文档都代表主节点上执行的一个操作。从服务器会定期从主服务器中获取oplog记录,然后在本机上执行!对于存储oplog的集合,MongoDB采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!主节点通过--oplogSize设置oplog的大小(主节点操作记录存储到local的oplog中)
=============================================================================================MongoDB同步也并非只能从主节点同步,假设集群中3个节点,节点1是主节点在IDC1,节点2、节点3在IDC2,初始化节点2、节点3会从节点1同步数据。后面节点2、节点3会使用就近原则从当前IDC的副本集中进行复制,只要有一个节点从IDC1的节点1复制数据。设置mongodb、同步还要注意以下几点:
[1] secondary不会从delayed(延迟)和hidden(隐藏)成员上复制数据。 [2] 要是需要同步,两个成员的buildindexes必须要相同无论是否是true和false。 [3] buildindexes主要用来设置是否这个节点的数据用于查询,默认为true。 [4] 如果同步操作30秒都没有反应,则会重新选择一个节点进行同步。4)Mongodb主节点的读写压力过大如何解决?
在系统早期,数据量还小的时候不会引起太大的问题,但是随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的。而MongoDB主打的就是海量数据架构,它不能解决海量数据怎么行! mongodb的"分片"就是用来解决这个问题的。传统数据库怎么做海量数据读写?其实一句话概括:分而治之。如下TaoBao早期的一个架构图:
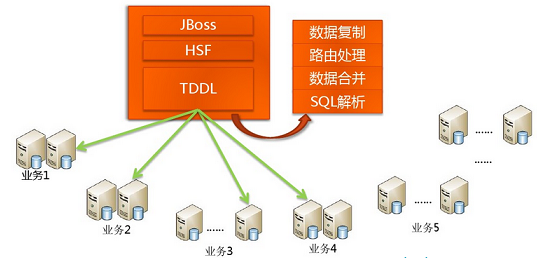
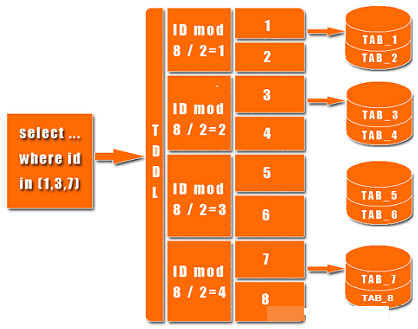
上图中有个TDDL,是TaoBao的一个数据访问层组件,它主要的作用是SQL解析、路由处理。根据应用的请求的功能解析当前访问的sql判断是在哪个业务数据库、哪个表访问查询并返回数据结果。具体如图:
说了这么多传统数据库的架构,那NoSQL怎么去做到了这些呢?MySQL要做到自动扩展需要加一个数据访问层用程序去扩展,数据库的增加、删除、备份还需要程序去控制。一但数据库的节点一多,要维护起来也是非常头疼的。不过MongoDB所有的这一切通过它自己的内部机制就可以搞定的了。如下图看看MongoDB通过哪些机制实现路由、分片:
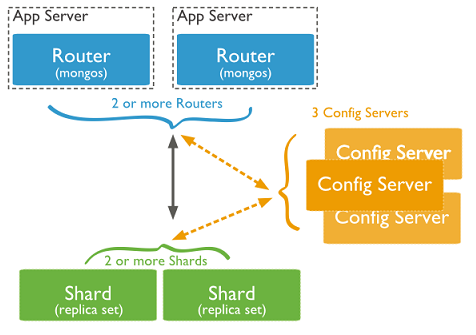
从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货, mongodb集群就不会挂掉。
shard,这就是传说中的分片了。上面提到一个机器就算能力再大也有天花板,就像军队打仗一样,一个人再厉害喝血瓶也拼不过对方的一个师。俗话说三个臭皮匠顶个诸葛亮,这个时候团队的力量就凸显出来了。在互联网也是这样,一台普通的机器做不了的多台机器来做,如下图:
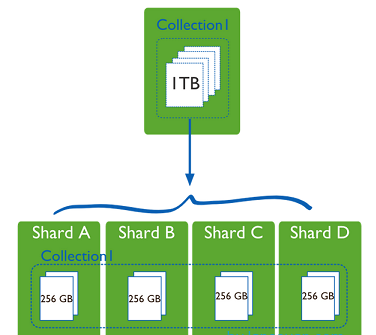
一台机器的一个数据表 Collection1 存储了 1T 数据,压力太大了!在分给4个机器后,每个机器都是256G,则分摊了集中在一台机器的压力。也许有人问一台机器硬盘加大一点不就可以了,为什么要分给四台机器呢?不要光想到存储空间,实际运行的数据库还有硬盘的读写、网络的IO、CPU和内存的瓶颈。在mongodb集群只要设置好了分片规则,通过mongos操作数据库就能自动把对应的数据操作请求转发到对应的分片机器上。在生产环境中分片的片键可要好好设置,这个影响到了怎么把数据均匀分到多个分片机器上,不要出现其中一台机器分了1T,其他机器没有分到的情况,这样还不如不分片!
replica set(副本集),其实上图4个分片如果没有 replica set 是个不完整架构,假设其中的一个分片挂掉那四分之一的数据就丢失了,所以在高可用性的分片架构还需要对于每一个分片构建 replica set 副本集保证分片的可靠性。生产环境通常是 2个副本 + 1个仲裁(即一主一从一仲裁)。
5)MongoDB 复制集节点增加移除及节点属性配置
复制集(replica Set)或者副本集是MongoDB的核心高可用特性之一,它基于主节点的oplog日志持续传送到辅助节点,并重放得以实现主从节点一致。再结合心跳机制,当感知到主节点不可访问或宕机的情形下,辅助节点通过选举机制来从剩余的辅助节点中推选一个新的主节点从而实现自动切换。对于一个已经存在的MongoDB Replica Set集群,可以对其进行节点的增加,删除,以及修改节点属性等等。1)查看当前版本环境repSetTest:PRIMARY> db.version()3.2.11注意:利用rs.add和rs.remove是不用rs.reconfig来使用配置生效的。2)删除节点repSetTest:PRIMARY> rs.remove("192.168.10.220:27000"){ "ok" : 1 }移除节点后的状态信息repSetTest:PRIMARY> rs.status() 移除后查看配置文件repSetTest:PRIMARY> rs.config()---------------------------------------------------------------------repmore:PRIMARY> config = {_id:"repmore",members:[{_id:0,host:'192.168.10.220:27017',priority :2}]}; //删除节点 repmore:PRIMARY> rs.reconfig(config); //使配置生效 repmore:PRIMARY> rs.status(); //查看节点状态 ---------------------------------------------------------------------3)增加节点repSetTest:PRIMARY> rs.add("192.168.10.220:27000")repSetTest:PRIMARY> rs.status()repSetTest:PRIMARY> rs.config()---------------------------------------------------------------------或者使用下面方法添加节点:repmore:PRIMARY> config = {_id:"repmore",members:[{_id:0,host:'192.168.10.220:27017',priority :2},{_id:1,host:'192.168.10.220:27018',priority:1}]}; //添加节点 repmore:PRIMARY> rs.reconfig(config); //使配置生效 repmore:PRIMARY> rs.status(); //查看节点状态注意:新增节点的replSet要和其他节点要一样---------------------------------------------------------------------4)启用Arbiter节点repSetTest:PRIMARY> rs.remove("192.168.10.220:27000")repSetTest:PRIMARY> rs.add({host:"192.168.10.220:27000",arbiterOnly:true})对于Arbiter也可以使用rs.addArb函数来添加> rs.addArb("192.168.10.220:27000") 6)MongoDB复制集状态查看
复制集状态查询命令1)复制集状态查询:rs.status()2)查看oplog状态: rs.printReplicationInfo()3)查看复制延迟: rs.printSlaveReplicationInfo()4)查看服务状态详情: db.serverStatus()====================================================================1)rs.status()self:只会出现在执行rs.status()命令的成员里uptime:从本节点 网络可达到当前所经历的时间lastHeartbeat:当前服务器最后一次收到其心中的时间Optime & optimeDate:命令发出时oplog所记录的操作时间戳pingMs: 网络延迟syncingTo: 复制源stateStr:可提供服务的状态:primary, secondary, arbiter即将提供服务的状态:startup, startup2, recovering不可提供服务状态:down,unknow,removed,rollback,fatal2)rs.printReplicationInfo()log length start to end: 当oplog写满时可以理解为时间窗口oplog last event time: 最后一个操作发生的时间3).rs.printSlaveReplicationInfo()复制进度:synedTo落后主库的时间:X secs(X hrs)behind the primary4).db.serverStatus()可以使用如下命令查找需要用到的信息db.serverStatus.opcounterRepldb.serverStatus.repl5).常用监控项目:QPS: 每秒查询数量I/O: 读写性能Memory: 内存使用Connections: 连接数Page Faults: 缺页中断Index hit: 索引命中率Bakground flush: 后台刷新Queue: 队列
7)MongoDB复制集常用监控工具
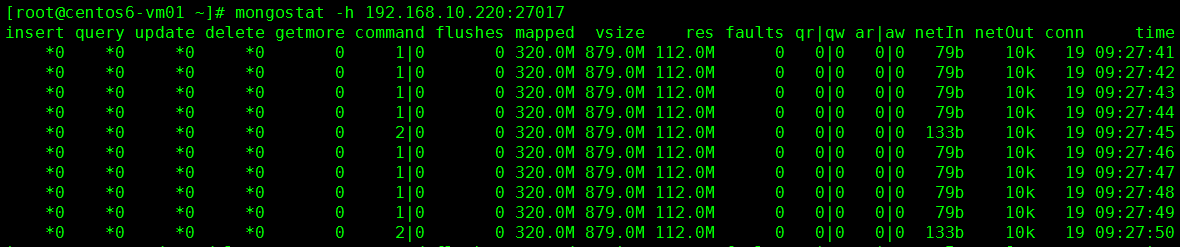
1) mongostat-h, --host 主机名或 主机名:端口--port 端口号-u ,--uername 用户名(验证)-p ,--password 密码(验证)--authenticationDatabase 从哪个库进行验证--discover 发现集群某个其他节点[root@centos6-vm01 ~]# mongostat -h 192.168.10.220:27017 [root@centos6-vm01 ~]# mongostat -h 192.168.10.220:27017 --discover mongostat重点关注的字段:getmore 大量的排序操作在进行faults 需要的数据不在内存中locked db 锁比例最高的库index miss 索引未命中qr|qw 读写产生队列,供求失衡
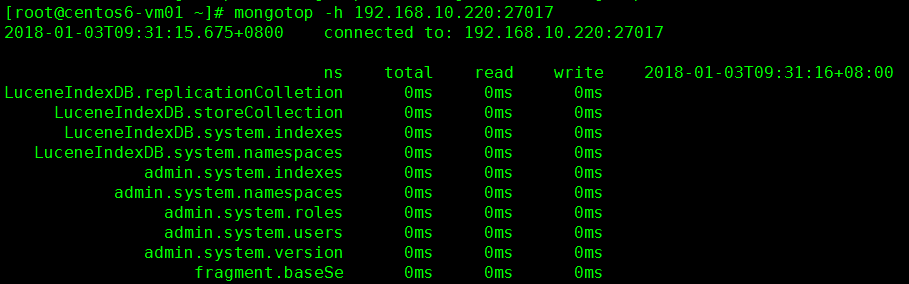
2) mongostop:与mongostat基本一样-h, --host 主机名或 主机名:端口--port 端口号-u ,--uername 用户名(验证)-p ,--password 密码(验证)--authenticationDatabase 从哪个库进行验证
8)对于Secondary来说有几个比较重要的属性:Priority优先级、Vote投票节点、Hidden节点、Delayed节点
设定节点的优先级别(Priority)
Priority=0 即优先级为0的节点。字面上来说,权限为0。拥有最低的权限。已然是Secondary了,权限还最低,啥影响呢?之前说过,mongoDB的副本集中是有投票机制的,如果一个Primary不可达,那么所有的Secondary会联合起来投票选举,选出心目中的新的Primary。因为只有Primary才能接收Writes的操作,所以Primary在一个mongoDB的集群中是必须的。下图展示了一个在两个IDC中存放Primary,Secondary,以及一个Priority=0的Secondary的场景(关于这个存放方式以及奇数偶数。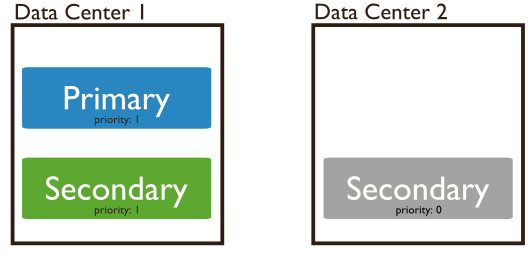
优先级为0的节点的特点
1)此节点丧失了当选Primary的机会。永远不会上位。2)此节点正常参与Primary产生的oplog的读取,进行数据备份和命令执行。3)此节点正常参与客户端对于数据的读取,进行担当负载均衡的工作。4)此节点虽然不能当选Primary但是却可以投票,很民主。
Priority=0在mongoDB中的解释就是一个Standby,可投票不可参选,又干活又负载。有点像日本议会党派中刚入党派的小喽啰,可以参与自己党派党首的选举,还要干好多活,外面民众开骂还得挡着,但就是不可能当选党首。
1)优先级用于确定一个倾向成为主节点的程度。取值范围为0-1002)Priority 0节点的选举优先级为0,不会被选举为Primary,这样的成员称为被动成员3)对于跨机房复制集的情形,如A,B机房,最好将『大多数』节点部署在首选机房,以确保能选择合适的Primary4)对于Priority为0节点的情况,通常作为一个standby,或由于硬件配置较差,设置为0以使用不可能成为主如下示例,在新增节点的时候设定该节点的优先级别repSetTest:PRIMARY> rs.add({"_id":3,"host":"localhost:27000","priority":1.5})也可以通过下面的方式修改优先级别repSetTest:PRIMARY> var config=rs.config()repSetTest:PRIMARY> config.members[2].priority=22repSetTest:PRIMARY> rs.reconfig(config){ "ok" : 1 } 投票节点(Vote)
1)投票节点不保存数据副本,不可能成为主节点。2)Mongodb 3.0里,复制集成员最多50个,参与Primary选举投票的成员最多7个。3)对于超出7个的其他成员(Vote0)的vote属性必须设置为0,即不参与投票。
隐藏节点(Hidden)
字面上来说,隐藏。这个隐藏式对客户端的隐藏,客户端如果要读取Secondary的数据,永远无法读取Hidden节点的数据,因为设置了Hidden的这个节点对于客户端是透明的,不可见。但是,对于自己的Secondary的群体和Primary来说都是可见的,所以,Hidden依然可以投票,依然要按照oplog进行命令的复制,只是,不参与负载了。Hidden属性的前提是必须是一个Priority=0的节点,所以会具备一些优先级=0的特点,具体如下。
Hidden节点的特点
1)此节点丧失了当选Primary的机会。永远不会上位。2)此节点正常参与Primary产生的oplog的读取,进行数据备份和命令执行。3)此节点正常参与客户端对于数据的读取,进行担当负载均衡的工作。4)此节点不参与客户端对于数据的读取,不进行负载均衡5)此节点虽然不能当选Primary但是却可以投票,也很民主。
第3条特征体现出它与Priority=0的不同地方,第4条特征表现出它比0优先级多出来的特性。如果节点是Hidden,它不参与负载,那么空闲出来的时间可以做一些赋予给它的特殊任务,比如数据备份等等。到应用场景的时候会有用处。
1)Hidden节点不能被选为主(Priority为0),并且对Driver不可见。2)因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务3)隐藏节点成员建议总是将其优先级设置为0(priority 0)4)由于对Driver不可见,因此不会作为read preference节点,隐藏节点可以作为投票节点5)在分片集群当中,mongos不会同隐藏节点交互> cfg = rs.conf()> cfg.members[2].priority = 0> cfg.members[2].hidden = true> rs.reconfig(cfg)查看设置为隐藏阶段后的属性repSetTest:SECONDARY> db.isMaster(){"hosts" : [ "localhost:27000", "localhost:27001" ], "setName" : "repSetTest", "setVersion" : 2, "ismaster" : false, "secondary" : true, "primary" : "localhost:27000", "passive" : true, "hidden" : true, //此处表明当前节点为隐藏节点 "me" : "localhost:27002", "maxBsonObjectSize" : 16777216, "maxMessageSizeBytes" : 48000000, "maxWriteBatchSize" : 1000, "localTime" : ISODate("2017-03-06T10:15:48.257Z"), "maxWireVersion" : 4, "minWireVersion" : 0, "ok" : 1} 延迟节点(Delayed)
字面上来说,迟延。迟延代表此节点的数据与Primary的数据有一定的迟延,通过设定一个迟延的属性来确定。假设,Primary的数据是10:00的最新数据,我们设置了一个3600秒的迟延参数,那么这个带有迟延的节点的数据或者说命令执行情况(在oplog中)应该只到9:00为止。与主节点有1小时的迟延。有些人可能会问,我们设计分布式数据库要的就是数据能够尽量避免迟延来达到一致,这样才能更好的提供服务,为什么要刻意制造迟延呢?试想这个场景:一个猪一样的队友在mongoDB的Replica集群上面执行了一个Drop操作,这个操作干掉了你的Primary的Collection,这个Drop同时被记录到oplog中去,其他的Secondary看到这个oplog后争相执行,各自干掉了自己的Collection,你苦心存储的数据就这么消失了。。。再怎么抽这个队友没用啊。所以,主动的过失避免就显得格外重要。如果你有一个Delayed节点,有一个1000秒的迟延,那么在你发现这个miss之后还有足够的时间可以响应去不让这个Delayed节点执行错误的command,从而挽回你的损失。具体如下。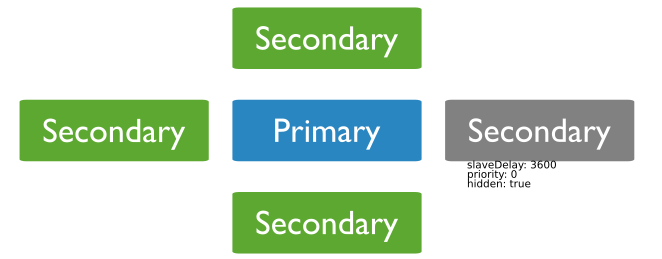
Delayed节点的特点
1)此节点必须是一个Priority=0且为Hidden的节点,因为Hidden必须是Priority=0的,所以此节点必须是Hidden的。2)此节点虽然又迟延又Hidden但是还是可以投票,也很民主。
Delayed节点的最大作用是用来容人为的灾,猪一样的操作,驴一样的动作,在Delayed节点可以把损失降到最低。当然,如果你在Delayed时间经过后发现了错误,那么只能"呵呵"了。Delayed的时间设定一定要大于响应时间,比如从Primary的oplog写到Secondary需要1秒,那么Delayed必须大于等于1秒,小于1秒的的话只能是一个不可及状态。
延迟节点包含复制集的部分数据,是复制集数据的子集延迟节点上的数据通常落后于Primary一段时间(可配置,比如1个小时)。当人为错误或者无效的数据写入Primary时,可通过Delayed节点的数据进行回滚延迟节点的要求:1)优先级别为0(priority 0),避免参与primary选举2)应当设置为隐藏节点(以避免应用程序查询延迟节点)3)可以作为一个投票节点,设置 members[n].votes 值为1延迟节点注意事项: 1)延迟时间应当等于和大于维护窗口持续期2)应当小于oplog容纳数据的时间窗口 repSetTest:SECONDARY> cfg = rs.conf()repSetTest:SECONDARY> cfg.members[2].priority = 0repSetTest:SECONDARY> cfg.members[2].hidden = truerepSetTest:SECONDARY> cfg.members[2].slaveDelay = 3600repSetTest:SECONDARY> rs.reconfig(cfg)repSetTest:SECONDARY> db.isMaster(){ "hosts" : [ "localhost:27000", "localhost:27001" ], "setName" : "repSetTest", "setVersion" : 3, "ismaster" : false, "secondary" : true, "primary" : "localhost:27000", "passive" : true, "hidden" : true, "slaveDelay" : 3600, //此处表面当前节点具有延迟属性,为延迟节点 "me" : "localhost:27002", "maxBsonObjectSize" : 16777216, "maxMessageSizeBytes" : 48000000, "maxWriteBatchSize" : 1000, "localTime" : ISODate("2017-03-06T10:19:57.148Z"), "maxWireVersion" : 4, "minWireVersion" : 0, "ok" : 1} mongodb副本集修改配置问题
因ip地址被占用,需要重新设置ip地址,这时需要修改副本集中的IP地址配置:1)查看配置rs.config();需要找到primary主机,在该主节点服务器上才有权限修改配置2)rs.remove("ip:port") 移除原配置文件中的已经变更地址的主机3)rs.add("ip:port") 添加新的地址主机4)设置priority优先级> var config = rs.config()> config.members[2].priority=2> rs.reconfig(config) //重新更新配置 9)其他维护说明
一、新增副本集成员1)登录primary2)>use admin >rs.add("new_node:port") 或者>rs.add({"_id":4,"host":"new_node:port","priority":1,"hidden":false}) 3)>use admin>rs.addArb("new_node:port") 或者 >rs.addArb({"_id":5,"host":"new_node:port"})或者>rs.add({'_id':5,"host":"new_node:port","arbiterOnly":true})仲裁者唯一的作用就是参与选举,仲裁者并不保存数据,也不会为客户端提供服务。成员一旦以仲裁者的身份加入副本集中,它就永远只能是仲裁者,无法将仲裁者重新配置为非仲裁者,反之亦然。最多只能有一个仲裁者每个副本集中。温馨提示:如果复制集中 priority=1 (默认),调用rs.add("new_node:port") 该命令 会产生 主从切换 即选举操作;如果复制集中 priority=1 (默认),直接调用rs.remove("new_node:port") 该命令 也会产生 主从切换 ; 二、删除副本集成员1)登录要移除的目标mongodb实例;2)利用shutdownServer()命令关闭实例;即 db.shutdownServer()3)登录复制集的primary;4)primary>use adminprimary>rs.remove("del_node:port"); 三、修改成员的优先级及隐藏性1)登录primary2)>use admin >conf=rs.conf()>conf.members[1].priority=[0-1000]>conf.members[1].hidden=true #priority必须为0>conf.members[9].tags={"dc":"tags_name1"} >rs.reconfig(conf); # 强制重新配置 rs.reconfig(conf,{"force":true})成员的属性有下列选项 [, arbiterOnly : true] [, buildIndexes : ] [, hidden : true] [, priority: ] [, tags: {loc1 : desc1, loc2 : desc2, ..., locN : descN}] [, slaveDelay : ]#秒为单位。 [, votes : 如果该成员要设置为 隐藏(hidden:true) 或延迟(slaveDelay:30) 则其优先级priority必须设置为 0;也就是说 隐藏成员和延迟成员及buildIndexs:false的成员 的优先级别一定必须是0 即priority=0.优先级为0的成员不能发起选举操作。只要优先级>0即使该成员不具有投票资格,也可以成为主节点。如果某个节点的索引结构和其他节点上的索引结构不一致,则该节点就永远不会变为主节点。优先级用于表示一个成员渴望成为主节点的程度。优先级的取值范围是[0-100],默认为1。优先级为0的成员永远不能成为主节点。使用rs.status()和rs.config()能够看到隐藏成员,隐藏成员只对rs.isMaster()不可见。客户端连接到副本集时,会调用rs.isMaster()来查看可用成员。将隐藏成员设定为非隐藏成员,只需将配置中的hidden设定为false,或删除hidden选项。每个成员可以拥有多个标签tags {“dc":"tags_name2",qty:"tag_name3"}votes:0 代表阻止这些成员在选举中投主动票,但是他们仍然可以投否决票。 修改副本集成员配置时的限制:1)不能修改_id;2)不能讲接收rs.reconfig命令的成员的优先级设置为 0;3)不能将仲裁者成员变为非仲裁者成员,反正亦然;4)不能讲 buildIndexes:false 改为 true; 四、查看副本集成员数据同步(延迟)情况>db.printReplicationInfo();>db.printSlaveReplicationInfo();#最好在secondary上执行>rs.printReplicationInfo()>rs.printSlaveReplicationInfo()>use local>db.slaves.find()在主节点上跟踪延迟:local.slaves该集合保存着所有正从当前成员进行数据同步的成员,以及每个成员的数据新旧程度。登录主节点>use local>db.slaves.find()、查看其中每个成员对应的"syncedTo":{"t":9999999,"i":32} 部分即可知道数据的同步程度。"_id"字段的值是每个当前成员服务器标识符。可以到每个成员的local.me.find()查看本服务器标识符。1)如果多台服务器拥有相同的_id标识符,则依次登录每台服务器成员,删除local.me集合(local.me.dorp()),然后重启mongodb,重启mongod后,mongod会使用新的“_id”重新生成local.me集合。 2)如果服务器的地址改变但_id没有变,主机名变了,该情况会在本地数据库的日志中看到重复键异常(duplicate key exception)。解决方法是:删除local.slaves集合即可,不需要重启mongod。 因为mongod不会清理local.slaves集合,故里面的数据可能不准确或过于老旧,可将整个集合删除。当有新的服务器将当前成员作为复制源时,该集合会重新生成。如果在主节点中看到了某个特定的服务器在该集合中有多个文档,即表示备份节点之间发生了复制链,该情况不影响数据同步,只是把每个备份节点的同步源告诉主节点。 删除local.me集合,需要重新启动mongod,mongod启动时会使用新的 _id重新生成local.me集合。 删除local.slaves集合,不用重启mongod。该集合中的数据是记录该成员被作为同步源的服务器的数据。该集合用于报告副本集状态。删除后不久如果有新的节点成员将该服务器节点作为复制源,该集合就会重新生成。 五、主节点降为secondary>use admin>rs.stepDown(60)#单位为 秒 六、锁定指定节点在指定时间内不能成为主节点(阻止选举)>rs.freeze(120)#单位为 秒释放阻止>rs.freeze(0) 七、强制节点进入维护模式(recovering)可以通过执行replSetMaintenanceMode命令强制一个成员进入维护模式。例如自动检测成员落后主节点指定时间,则将其转入维护模式:>function maybeMaintenanceMode(){var local=db.getSisterDB("local");if (!local.isMaster().secondary){return;)var last=local.oplog.rs.find().sort({"$natural":-1}).next();var lasttime=last['ts']['t'];if (lasttime<(new date()).getTime()-30){db.adminCommand({"replSetMaintenanceMode":true});}};将成员从维护模式转入正常模式。即恢复:>db.adminCommand({"replSetMaintenanceMode":false}); 八、阻止创建索引(不可再修改为可以创建索引,故慎重考虑)通常会在备份节点的延迟节点上设置阻止创建索引。因为该节点通常只是起到备份数据作用。设置选项 buildIndexs:false即可。该选项是永久性的。如果要将不创建索引的成员修改为可以创建索引的成员,那么必须将这个成员从副本集中移除,再删除它上的所有数据,最后再将其重新添加到副本集中。并且允许其重新进行数据同步。该选项也要求成员的优先级为 0. 九、指定复制源(复制链) 查看复制图谱使用db.adminCommand({"replSetGetStatus":1})['syncingTo'] 可以查看复制图谱(每个节点的同步源);在备份节点上执行 rs.status()['sysncingTo'] 同样可以查看复制图谱(同步源);mongodb是根据ping时间来选择同步源的,会选择一个离自己最近而且数据比自己新的成员作为同步源。可以使用replSetSyncFrom 命令来指定复制源或使用辅助函数rs.sysncFrom()来修改复制源。db.adminCommand({"replSetSyncFrom":"server_name:port"}); 副本集默认情况下是允许复制链存在的,因为这样可以减少网络流量。但也有可能花费是时间更长,因为复制链越长,将数据同步到全部服务器的时间有可能就越长(比如每个备份节点都比前一个备份节点稍微旧点,这样就得从主节点复制数据)。解决方法:1)手动改变复制源登录备份节点:>use admin>db.adminCommand({"replSetSyncFrom":"新复制源"})或者>rs.syncFrom("新复制源")副本集中的成员会自动选择其他成员作为复制源。这样就会产生复制链。如果一个备份节点从另一个备份节点(而非主节点)复制数据时,就会形成复制链。复制链是可以被禁用的,这样就可以强制要求所有备份节点都从主节点复制数据。 禁用复制链:即禁止备份节点从另一个备份节点复制数据。>var config=rs.config()>config.settings=config.settings ||{}>config.settings.chainingAllowed=false>rs.reconfig(config); 十、强制修改副本集成员>var config=rs.config()>config.member[n].host=...>config.member[n].priority=........>rs.reconfig(config,{"force":true}) 十一、修改Oplog集合的大小如果是主节点,则先将primary 降为 secondary。最后确保没有其他secondary 从该节点复制数据。rs.status()1)关闭该mongod服务 use admin >db.adminCommand({shutdownServer:1});2)以单机方式重启该mongod(注释掉 配置文件中的 replSet shardsvr ,修改端口号)3)将local.oplog.rs中的最后一条 insert 操作记录保存到临时集合中> use local>var cursor=db.oplog.rs.find({"op":"i"});>var lastinsert=cursor.sort({$natural:-1}).limit(1).next();>db.templastop.save(lastinsert);>db.templastop.findOne()#确保写入4)将oplog.rs 删除: db.oplog.rs.drop();5)创建一个新的oplog.rs集合: db.createCollection("oplog.rs":{"capped":true,"size":10240});6)将临时集合中的最后一条insert操作记录写回新创建的oplog.rs:>var temp=db.templastop.findOne();>db.oplog.rs.insert(temp);>db.oplog.rs.findOne() #确保写回,否则 该节点重新加入副本集后会删除该节点上所有数据,然后重新同步所有数据。7)最后将该节点以副本集成员的身份重新启动即可。 十二、为复制集成员设置选项即当运行rs.initiate(replSetcfg) 或运行 rs.add(membercfg)选项时,需要提供描述复制集成员的特定配置结构:{_id:replSetName,members:[{_id: ,host: ,[priority: ,]#默认值为1.0.即选项的值是浮点型[hidden:true,]#该元素将从db.isMaster()的输出中隐藏该节点。[arbiterOnly:true,]#默认值为 false[votes: ,]#默认值为1 。改选项的值为整形[tags:{documents},][slaveDelay: ,][buildIndexes:true,]#默认值为 false。该选项用于禁止创建索引。}],settings:{[chainingAllowed: ,]#指定该成员是否允许从其他辅助服务器复制数据。默认值为 true[getLastErrorModes: ,]#模式:用于自定义写顾虑设置[getLastErrorDefaults: ,]#默认值:用于自定义写顾虑设置。}}以上是复制集的完整的配置结构。最高级的配置结构包括3级:_id、members、settings。_id是复制集的名称,与创建复制集成员时时候用的 --replSet命令选项时提供的名称一样。members是数组,由一个描述每个成员的集合组成;这是添加单个服务器到集合中时,应该在rs.add()命令中提供的成员机构;settings也是数组,该settings数组包含应用到整个复制集的选项。这些选项可以设置复制集成员间如何通信。 十三、Rollbackmongodb只支持小于300M的数据量回滚,如果大于300M的数据需要回滚或要回滚的操作在30分钟以上,只能是手动去回滚。会在mongodb日志中报以下错误:[replica set sync] replSet syncThread: 13410 replSet too much data to roll back经量避免让rollback发生。方法是:使用 复制的 写顾虑(Write Concern)规则来阻止回滚的发生。如果发生了回滚操作,则会在mongodb数据文件目录下产生一个以database.collection.timestamp.bson的文件。查看该文件的内容用 bsondump 工具来查看。 十四、读偏好设置(ReadPreferred)读取偏好是指选择从哪个复制集成员读取数据的方式。可以为驱动指定5中模式来设置读取偏好。readPreference=primary|primaryPreferred|secondary|secondaryPreferred|nearestsetReadPreferred()命令设置读取偏好。 primary:只从主服务器上读取数据。如果用户显式指定使用标签读取偏好,该读取偏好将被阻塞。这也是默认的读取偏好。primaryPreferred:读取将被重定向至主服务器;如果没有可用的主服务器,那么读取将被重定向至某个辅助服务器;secondary:读取将被重定向至辅助服务器节点。如果没有辅助服务器节点,该选项将会产生异常;secondaryPreferred:读取将被重定向至辅助服务器;如果没有辅助服务器,那么读取将被重定向至主服务器。该选项对应旧的“slaveOK”方法;nearest:从最近的节点读取数据,不论它是主服务器还是辅助服务器。该选项通过网络延迟决定使用哪个节点服务器。 十五、写顾虑设置(Write Concern)写顾虑类似读取偏好,通过写顾虑选项可以指定在写操作被确认完成前,数据必须被安全提交到多少个节点。写顾虑的模式决定了写操作时如何持久化数据。参数“w”会强制 getLastError等待,一直到给定数据的成员都执行完了最后的写入操作。w的值是包含主节点的。写顾虑的5中模式:w=0或不确定:单向写操作。写操作执行后,不需要确认提交状态。 w=1或确认:写操作必须等到主服务器的确认。这是默认行为。w=n或复制集确认:主服务器必须确认该写操作。并且n-1个成员必须从主服务器复制该写入操作。该选项更强大,但是会引起延迟。w=majority:写操作必须被主服务器确认,同时也需要集合中的大多数成员都确认该操作。而w=n可能会因为系统中断或复制延迟引起问题。j=true日志:可以与w=写顾虑一起共同指定写入操作必须被写入到日志中,只有这样才算是确认完成。wtimeout:避免getLastError一直等待下去,该值是命令的超时时间值,如果超过这个时间还没有返回,就会返回失败。该值的单位是毫秒。如果返回失败,值在规定的时间内没有将写入操作复制到"w"个成员。该操作只对该连接起作用,其他连接不受该连接的"w"值限制。db.products.insert({ item : "envelopes" , qty : 100 , type : "Clasp" },{ writeConcern : { w : 2 , wtimeout : 5000 } })wtimeout#代表5秒超时 修改默认写顾虑cfg = rs.conf()cfg.settings = {}cfg.settings.getLastErrorDefaults = { w: "majority" , wtimeout: 5000 }rs.reconfig(cfg) 设置写等待db.runCommand({"getLastError":1,w:"majority"})或db.runCommand({"getLastError":1,"w":"majority","wtimeout":10000})即,表示写入操作被复制到了多数个节点上(majority 或 数字),这时的 w会强制 getLastError等待,一直到给定数量的成员执行完了最后的写入操作。 而wtimeout是指超过这个时间没有返回则返回失败提示(即无法在指定时间内将写入操作复制到w个成员中),getLastError并不代表写操作失败了, 而是代表在指定给定wtimeout时间内没有将写入操作复制到指定的w个成员中。w是限制(控制)写入 速度,只会阻塞这个连接上的操作,其他连接上 的操作不受影响。 十六、读取偏好和写顾虑中使用标签(tags) 十七、选举机制1)自身是否能够与主节点连通;2)希望被选件为主节点的备份节点的数据是否最新;3)有没有其他更高优先级的成员可以被选举为主节点;4)如果被选举为主节点的成员能够得到副本集中“大多数”成员的投票,则它会成为主节点,如果“大多数”成员中只有一个否决了本次选举,则本次选举失败即就会取消。一张否决票相当于10000张赞成票。5)希望成为主节点的成员必须使用复制将自己的数据更新为最新; 十八、数据初始化过程1)首先做一些记录前的准备工作:选择一个成员作为同步源,在local.me集合中为自己创建一个标识符,删除索引已存在的数据库,以一个全新的状态开始进行同步;该过程中,所有的数据都会被删除。2)然后克隆,就是将同步源的所有记录全部复制到本地。3)然后就进入oplog同步的第一步,克隆过程中的所有操作都会被记录到oplog中。4)接下来就是oplog同步过程的第二步,用于将第一个oplog同步中的操作记录下来。5)截止当前,本地的数据应该与主节点在某个时间点的数据集完全一致了,可以开始创建索引了。6)若当前节点的数据仍然落后同步源,那么oplog同步过程的最后一步就是将创建索引期间的所有操作全部同步过出来,防止该成员成为备份节点。7)现在当前成员已经完成了初始化数据的同步,切换到普通状态,这时该节点就可以成为备份节点了。 十九、mongodb3.0 建议开启的设置# echo never > /sys/kernel/mm/transparent_hugepage/enabled# echo never > /sys/kernel/mm/transparent_hugepage/defrag执行上面两命令后只是当前起作用。如果重启mongod服务后 就失效。永久起效则写入到 /etc/rc.local即 二十、修改服务器hostname名1)首先修改 secondary 服务器的 hostname;然后 stop secondary;2)重启 secondary 以修改后的新hostname;3)登录 primary ;4)用rs.reconfig()命令修改 复制集的配置信息;>conf=rs.conf()>conf.members[x].host='new_address:27017'>rs.reconfig(conf); 二十一、生成 keyfile文件# openssl rand -base64 666 > /opt/mongo/conf/MongoReplSet_KeyFile# chown mongod.mongod /opt/mongo/conf/MongoReplSet_KeyFile# chmod 600 /opt/mongo/conf/MongoReplSet_KeyFile